Quantitative Fun With Fund Names
There are a number of hard problems in investing, for instance: 1) Finding alpha. 2) Finding clients and assets — especially if you can’t 1) consistently find alpha. 3) Finding an awesome name for your fund. The investing blogosphere is all over the first two. Now, for something completely different, we help you with the last one!
Inspired by Sloane Ortel’s post, we’ll run some analytics on a dataset of investment firm names, culminating in our very own algorithmic fund name generator.
Assembling data from various sources, scrubbing and deduplicating, we built a set of about 20,000 names.
As a warmup, here are the most frequent words found in company names:

The most frequent bigrams or 2-word combinations:

Word2Vec is an algorithm which, given a corpus of text, maps words to vectors of floating-point numbers, magically distilling syntactic and semantic attributes of each word.1 Vector representations of words are used for machine translation, sentiment analysis, intelligent personal assistants like Siri and Alexa, and other natural language processing applications. Word2Vec word vectors can be uncannily accurate in representing meanings and relationships between words.
We could train our own vectors, but this is not a large corpus, and there are many pre-trained vector sets based on the Web, Wikipedia, different languages and corpora. Let’s load the set of vectors trained on Google News, map our frequently used words, and cluster them.
|
Cluster 0 (522 words) [‘management’, ‘partners’, ‘co’, ‘services’, ‘global’, ‘international’, ‘research’, ‘new’, ‘national’, ‘mutual’] |
Cluster 1 (444 words) [‘inc’, ‘sa’, ‘hong’, ‘kong’, ‘de’, ‘al’, ‘deutsche’, ‘nv’, ‘ma’, ‘adv’] |
Cluster 2 (545 words) [‘life’, ‘fidelity’, ‘golden’, ‘royal’, ‘legacy’, ‘millennium’, ‘beacon’, ‘fortune’, ‘republic’, ‘heritage’] |
|
Cluster 3 (336 words) [‘capital’, ‘investment’, ‘asset’, ‘wealth’, ‘investments’, ‘holdings’, ‘fund’, ‘financial’, ‘company’, ‘ag’, ‘funds’, ‘trading’, ‘markets’, ‘investors’, ‘managers’] |
Cluster 4 (180 words) [‘pacific’, ‘north’, ‘creek’, ‘river’, ‘west’, ‘sun’, ‘south’, ‘northern’, ‘summit’, ‘ridge’] |
Cluster 5 (150 words) [‘eagle’, ‘tiger’, ‘lion’, ‘falcon’, ‘wolf’, ‘arrow’, ‘peregrine’, ‘owl’, ‘fur’, ‘fox’] |
|
Cluster 6 (223 words) [‘street’, ‘hill’, ‘estate’, ‘park’, ‘property’, ‘square’, ‘spa’, ‘lane’, ‘bridge’, ‘road’] |
Cluster 7 (656 words) [‘asia’, ‘uk’, ‘singapore’, ‘canada’, ‘pvt’, ‘japan’, ‘india’, ‘morgan’, ‘europe’, ‘australia’] |
Cluster 8 (725 words) [‘limited’, ‘holding’, ‘the’, ‘first’, ‘real’, ‘point’, ‘us’, ‘blue’, ‘one’, ‘old’] |
|
Cluster 9 (237 words) [‘alpha’, ‘amp’, ‘matrix’, ‘quantum’, ‘meridian’, ‘sigma’, ‘dimensional’, ‘constellation’, ‘symmetry’, ‘parametric’] |
Cluster 10 (106 words) [‘china’, ‘rock’, ‘stone’, ‘silver’, ‘kg’, ’emerald’, ‘steel’, ‘gold’, ‘diamond’, ‘mill’] |
Cluster 11 (207 words) [‘oak’, ‘tree’, ‘brown’, ‘wood’, ‘cypress’, ‘pine’, ‘harvest’, ‘grove’, ‘cedar’, ‘maple’] |
|
Cluster 12 (1413 words) [‘llc’, ‘ltd’, ‘lp’, ‘pte’, ‘pty’, ‘corp’, ‘gmbh’, ‘shanghai’, ‘hk’, ‘ubs’] |
Cluster 13 (108 words) [‘harbor’, ‘compass’, ‘banca’, ‘marine’, ‘spinnaker’, ‘anchorage’, ‘shipping’, ‘port’, ‘motor’, ‘mariner’] |
Cluster 14 (276 words) [‘advisors’, ‘group’, ‘advisory’, ‘private’, ‘corporation’, ‘trust’, ‘associates’, ‘counsel’, ‘consulting’, ‘advisers’] |
We distinguish clusters related to countries, geographical features, animals, trees, minerals and materials, nautical concepts, scientific and financial concepts, positive metaphors like ‘fidelity’ and ‘heritage’.
Plotting popular words from each cluster, and connecting words that are frequently co-located in the same firm names, we get

We can explore related words using Google’s Embeddings Projector, which generates 3D images of word relationships that look like this:
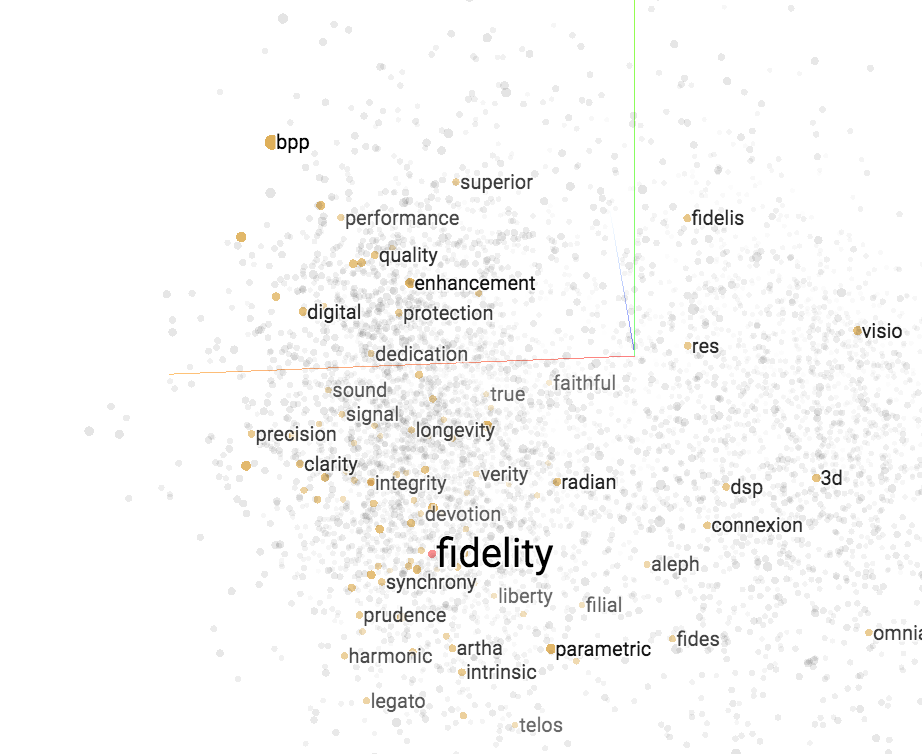
- Click on the link for the embeddings projector, wait for it to load the data.
- Start entering a word at top right to search for it
- Select the word you want in the list that gets populated
- Click “Isolate data points”
- Drag the image around with your mouse to see related words
- When you’re done, hit “Clear selection”
It’s a bit like taking a word and algorithmically free-associating similar words that are used in fund names.
Finally, we can train a machine learning algorithm to automatically generate realistic-sounding new names based on our corpus! Use this link or the form below to generate names based on a starting string (or leave blank).
Some names may be similar to existing names in the corpus, which are the property of their respective owners.
Other names are a bit random…use them for inspiration for your next corporate entity…or if you need to generate random realistic-looking text for testing purposes or to fool a spam filter. We make no representation about the regulatory compliance, appropriateness, or marketing value of generated names!
The code is here.
We hope this will free valuable time from the fund naming problem to let managers focus on generating alpha.
1 How does Word2Vec work? It’s like a Netflix movie recommendation system, but for words. The Netflix recommender maps each user and each movie to a vector. It tries to find</p>
1. A vector to represent each movie and
2. A vector to represent each user such that
3. When you multiply those two vectors, you get a number that predicts how the user will rate the movie.
As users rate a lot of movies and the system trains and improves the vectors, different vector components start to represent movie features, like action-adventure, rom-com, scifi, etc.
Now to see how Word2Vec assigns vectors to words, substitute the statement ‘user u likes movie m‘ with ‘the word goldman frequently occurs in same context as the word morgan‘.
By using a large corpus to train vectors which predict what words arise in similar context, we arrive at vectors that represent a sometimes-shockingly complex knowledge about each word, bordering on understanding. For instance, we might find that the word vector closest to ‘Paris’ _ ‘France’ + ‘Germany’ is ‘Berlin.’ In other words, Word2Vec in some sense understands that ‘Paris is to France as Berlin is to Germany.’ This post is a good intro.
</small>
2 Computer-generated names are generated as follows:</p>
(‘Wile’, ‘y’)
(‘Wiley E. Coy’, ‘o’)
(‘Wiley E. Coyote Investment Managemen’, ‘t’)
</small>