Truth, Lies, and ChatGPT
What ChatGPT really knows; the Darién Gap between wordcel AI and shape-rotator AI, what AI might mean for social construction of reality, and what we should do about it.
There are three kinds of lies: lies, damned lies, and statistics. - Mark Twain

What does ChatGPT actually know? Where does it falter? Where do we stand on the journey to Artificial General Intelligence (AGI)? What does generative AI mean for increasingly computer-mediated human reality?
Every new generation of media and tech since TV seems to make us dumber. How do we break the cycle and harness AI that makes us smarter, by helping us sort through the glut of information and misinformation and bullshit, instead of multiplying it?
Generative AI can manufacture infinite ‘truthy’ bullshit at near-zero cost, including ‘deepfake’ audio and video. And then it could potentially further train itself on the ones that go viral, concentrating fake ‘truth’ deep in our information infrastructure and knowledge frameworks. The singularity might prove a ‘singularity of bullshit’.
How do we engineer our hackable knowledge ecosystem to disrupt bullshit instead of perpetuating and magnifying it, and further intensifying the acid bath our shrinking attention spans soak in? How do we deal with deepfakes, misinformation, and other forms of AI-assisted fraud and bullshit?
First let’s explore what ChatGPT currently knows, and how it might evolve. Then, let’s discuss some takeaways and possible policy responses.
ChatGPT and bullshit

ChatGPT is remarkably good at bullshit. For example, let’s ask it to summarize the story of the movie “Titanic” in various styles, like a literary reviewer, or a Gen Z slacker, or Snoop Dogg.
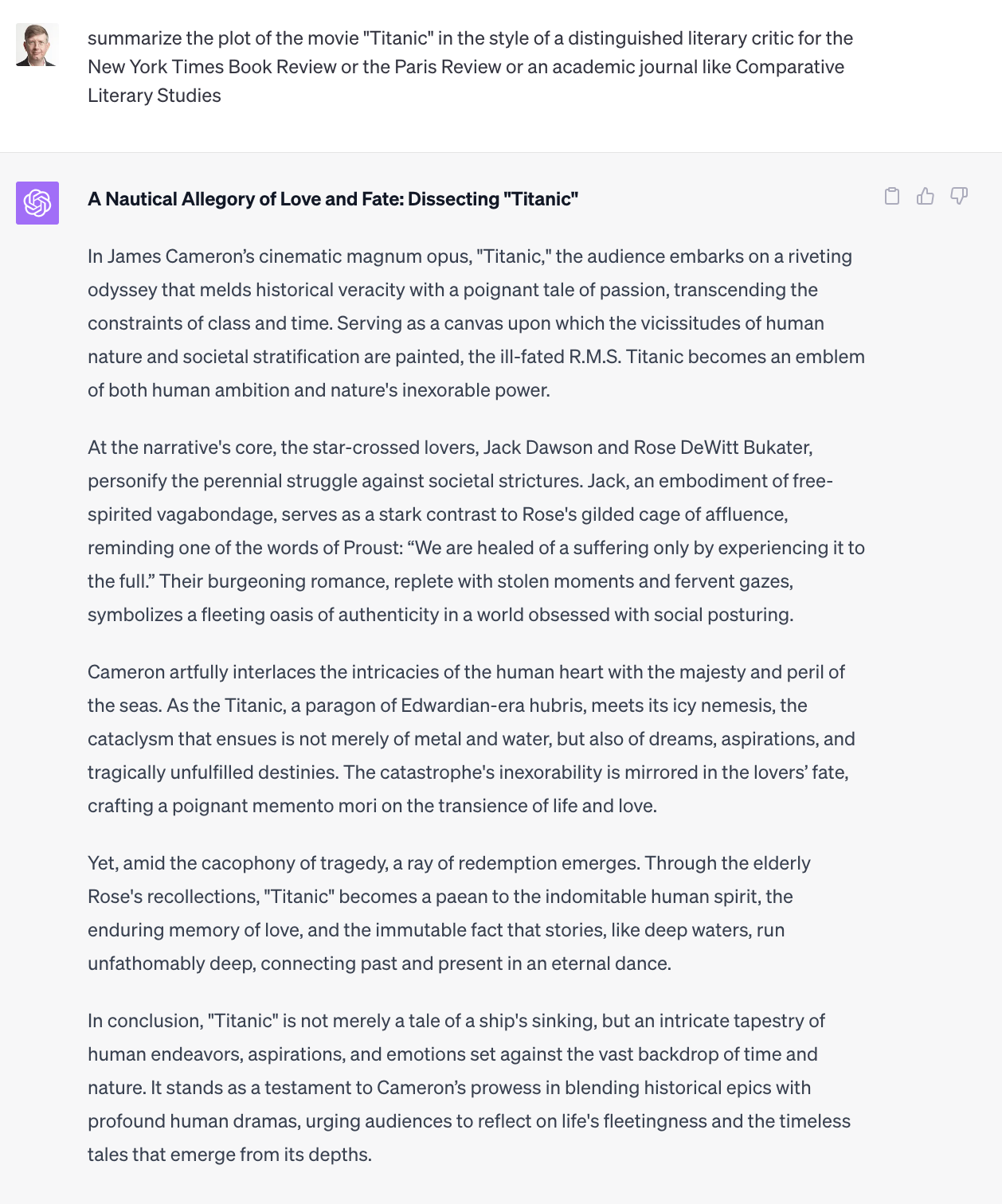

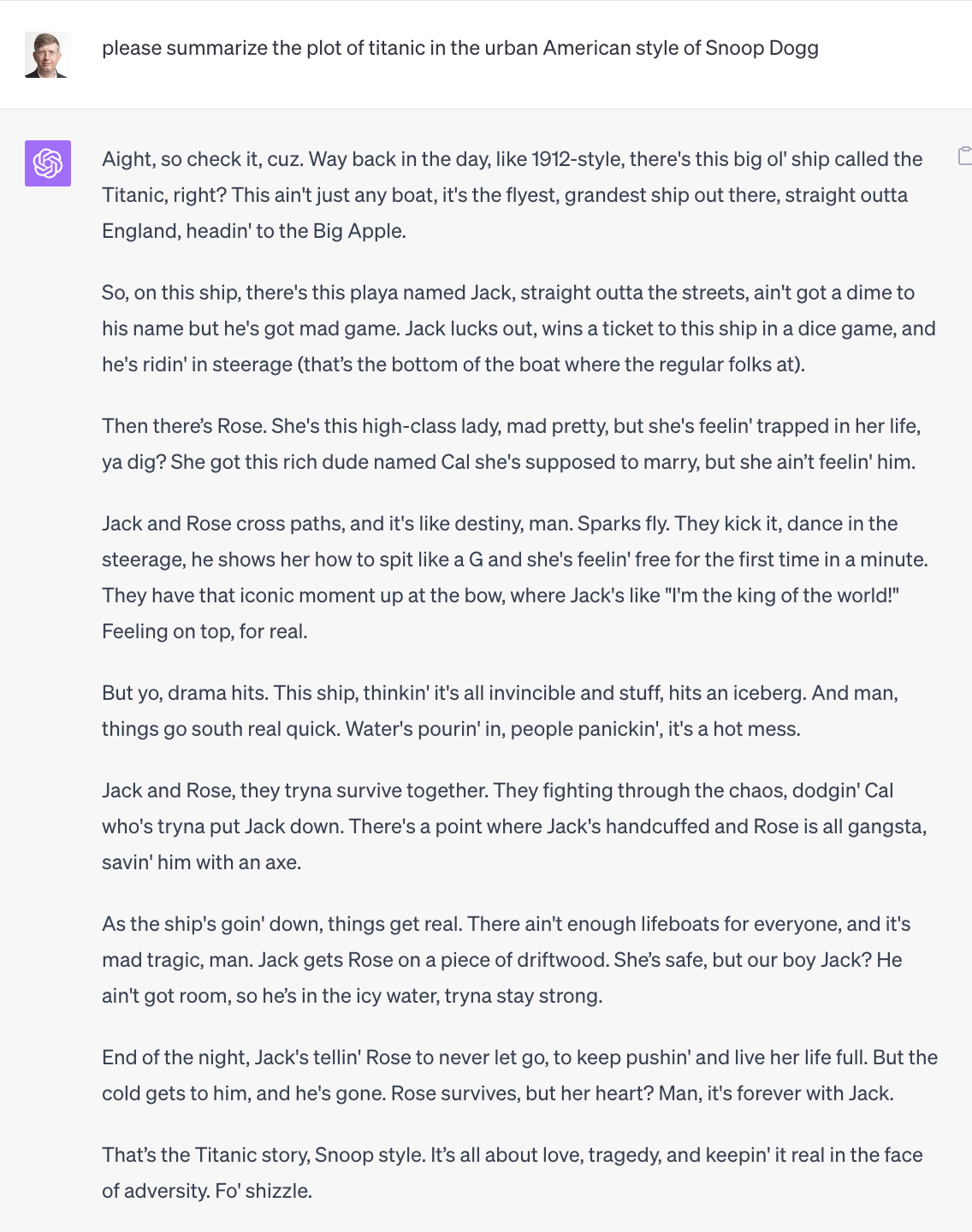
ChatGPT excels as a pattern matcher and mimic, ranking in the top 0.1% in verbal IQ by some measures. You can ask ChatGPT to respond in the voice of a Harvard history professor, or an FT or WSJ journalist, or a Goldman Sachs research analyst with deep knowledge of economics, finance, and investment management, or a McKinsey management consultant with expertise in corporate strategy and operations. And it will do a remarkable job. It can even write decent Harvard papers, which is of course the bullshit Olympics. If you want, you could tell ChatGPT you want all replies written in the language of incel rage bait, or a fictional persona like Holden Caulfield.
It seems likely that, within a few years, most professional writing and creative work will be done with the assistance of ChatGPT. (Using ‘ChatGPT’ as a shortcut for generative AI as a whole.) Feed ChatGPT your corporate style guide and examples of tone, voice and branding, and it will speed up and improve writing and knowledge work tasks. Its verbal mastery is essentially indistinguishable from human writing.
Artists, writers, video and other content creators might have to take a page from mountain climbers who characterize their ascents as ‘without oxygen’ or ‘free solo’, and specify what assistive AI tech was used. Everybody can now be a James Michener or Edward Stratemeyer, prolific ‘authors’ who used teams of assistants to operate content mills.
You can use the latent logic and reasoning inherent in language understanding and generation to create remarkable workflows: ask an agent to identify the best coffee grinder according to your criteria, fetch information from Google, verify it, condense it, make a recommendation based on data, and then succinctly summarize and explain it. Most complex tech will probably integrate ChatGPT assistants, supplementing or to some extent replacing existing UIs, APIs, and DSLs. An AI assistant like Microsoft Copilot, that knows you and your workflows and content creation style, might become the UI of first choice to many different applications, abstracting the UI from application layer.
Skeptics might say ChatGPT doesn’t have deep knowledge, and it’s all surface level bullshit, a criticism which has some (possiby skin-deep) validity. ChatGPT doesn’t actually ‘program’ like a computer science student does, which is to make a mental model of a novel problem and write code to solve it based on deep understanding of data structures and algorithms. What ChatGPT does is read all the code in existence, which a computer science student cannot. And then, if there is code out there similar to what you are trying to write, if will create something possibly amazing, or possibly pretty good but badly flawed. It might even make up modules and APIs it thinks it needs to perform a task. If you give it a novel Leetcode hard problem that it has never seen before, it will not solve it. ChatGPT has extensive knowledge but not deep understanding. It gives you ‘infinite interns’, but you have to give them very detailed direction, and they sometimes go off the rails regardless. The ugly Brandon Hunter screwup bodes poorly for AI journalism and office automation. It’s just a matter of time before the first major IT disaster fueled by generative AI, like when the Mars probe blew up due to a metric/Imperial error.
But contra the skeptics, ChatGPT does know a hell of a lot, and will keep getting better. Go to a random Wikipedia page and quiz ChatGPT on a fact, like who won the 1995 world women’s handball championship, and it will probably know the answer. And the GPT-4 paper shows it passed all these tests (note the poor math scores, we will come back to that):
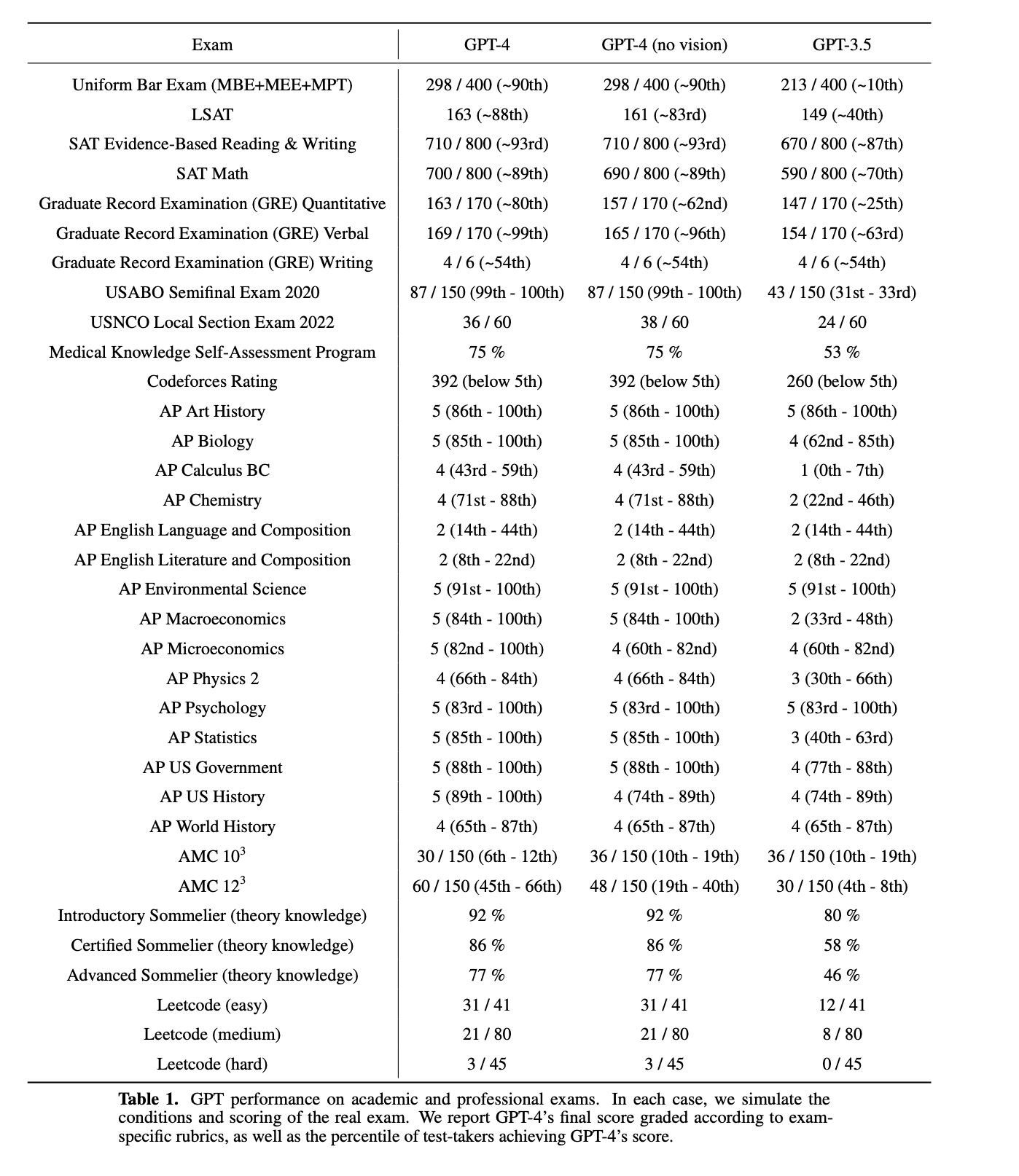
Carl Sagan said, “If you wish to make an apple pie from scratch, you must first invent the universe.” Similarly, if you wish to predict Shakespeare’s next token from scratch you must first fully model Shakespeare’s universe. A sufficiently immense statistical knowledge graph of linguistic relationships inherently captures a great deal of human knowledge. Just as constructing fluent language requires latent rhetorical reasoning, it also requires implicit factual knowledge.
On the other hand, it’s also possible to overestimate ChatGPT, to be lured by its linguistic fluency into the trap of thinking it is smarter than it is. This is the Eliza effect. It is real, and it is spectacular. Smart people ask ChatGPT to tackle complex questions like, make a psychological profile of this person based on this writing, rate this resume against this job description. It will happily generate sophisticated, articulate, confident answers that are totally wrong. And then generate totally different, highly persuasive answers the next time you ask the same question with perhaps a little twist.
ChatGPT is great at first-order language understanding and generation, information extraction, summarization. You can give it a second-order question like, what is the difference between a Les Paul Standard and a Les Paul Custom, and it will be quite helpful. You can give it chain-of-thought reasoning tasks like, here are a bunch of annual reports, give me compound annual growth rate in revenues for last 5 years, especially if you prompt it to think step by step. But chain-of-thought prompting can be taken too far and veer into telling ChatGPT what you want it to say.
Expecting ChatGPT to answer deep analytical questions at the level of a thoughtful, trained, experienced scientist or analyst is unrealistic. LLMs struggle at complex reasoning. Sure, you can tell ChatGPT it’s a chemistry professor with deep knowledge of flavors and fragrances, and it will sound like one, and be very confident and persuasive. But that doesn’t make it one. I’d be a bit cautious eating and drinking its recipes.
ChatGPT’s ability to bullshit is a trap. We will get a ton of terrible, directed reasoning, that sounds really persuasive and is supported by beautiful but misleading data visualization from the Advanced Data Analysis / Code Interpreter plugin. And even ‘evidence’ doctored by AI.
ChatGPT is an AI Ferdinand Waldo Damara. The exploits of Damara, dubbed The Great Impostor, exceed the famous Frank Abagnale’s possibly exaggerated frauds. Damara had a photographic memory and an exceptional IQ, and undoubtedly had the ability to be a legitimate doctor, or civil engineer, if not the character and temperament. Are you a surgeon because you have degrees and appointments, or because you save lives? To bullshit well, you have to know a lot about what you are doing.
Maybe what ChatGPT shows us is that a lot of people who seem smart are mostly really good stochastic parrots. Maybe the line between deceit, bullshit, cargo-culting and good research is finer than we think.
ChatGPT excels at plausible, ‘truthy’ explanations. It will happily make stuff up if you ask it about fictional characters or APIs. Fortunately, it’s such a people-pleaser that, if you merely instruct it to use only a specific source of truth, or to think step by step and be careful not to say anything that isn’t true, then it will generally avoid making stuff up. But it’s also so agreeable that if you tell it it’s wrong, it will just go along with you and parrot back whatever you told it, even if it’s wrong.
If you can keep ChatGPT grounded in reality and avoid situations where it goes off the rails, it is truly a force multiplier for knowledge work. It’s a huge step towards Artificial General Intelligence (AGI).
But it’s not AGI yet. Things that we would want a fully-developed AGI to do:
-
Sensory Perception. Cameras are great but human eyes are better, maybe 500 megapixels, wide dynamic range, heuristics to detect and track objects and integrate over time.
-
Filtering. Human senses transmit roughly 1GB/s of information to the brain. Most of the data is filtered before we become aware of it. We can only process maybe 120 bits of conscious awareness per second, on a half-second lag behind real-time. The preprocessing by the optic nerve and subconscious integration of various senses mean that by the time we are aware of something, it already makes sense. To play soccer like Messi, you have to train until your brain OODA-loops rings around your opponent without conscious thought.
-
Memory and representation. AGI would fit new facts into existing frameworks, and create new theories, models and frameworks to fit facts that don’t fit old patterns.
-
Abstraction. Using inductive reasoning, it would extrapolate from concrete examples to general principles and world models.
-
Deductive reasoning. It would use general models and principles to solve specific problems, identifying the best model and inputs to the model.
-
Autonomy. It would independently determine high-priority tasks and execute them without external prompts, based on its own values and objectives.
-
Adaptation. It would constantly learn and improve its policies.
-
Self-reflection. It would use introspection to reason about itself, evaluate its own progress, determine what it needs to learn and practice to achieve its objectives.
-
Flexibility. Creative solutions to complex novel problems.
-
Empathy. The ability to model other intelligent agents.
-
Systems thinking. The ability to model systems of agents, think strategically, and determine individual policies aligned with shared objectives. Ethical reasoning is basically strategic thinking, on a long timeframe, taking into account the objectives or welfare of multiple agents and their policy equilibria.
-
Communication. The ability to explain and communicate its thinking and actions to other intelligent agents, achieving cooperation and collaboration to pursue shared objectives.
-
Physical interaction. Robotic manipulation of complex novel environments.
-
Sentience. Striving for ‘consciousness’ seems like a fool’s errand. We can experience consciousness directly, but there is no test to know if an elephant or dolphin or octopus is sentient. It’s a poignant element of the human condition that we are social creatures, language creatures, but our most direct experiences are ones about which we can say and share very little. What we cannot speak of, we must pass over in silence.
ChatGPT is a giant leap forward. Unlike humans, computers are fungible and once we are able to create one intelligence, we will be able to create millions. Then, they will be able to communicate with each other at much higher rates than humans, self-improving rapidly. The singularity starts to come into focus. We’re maybe only a couple of ChatGPT-size leaps away, and the leaps might get easier because we can use the machine learning tools we built before to make the next leap. We’re not there, but maybe we can start to see it from here.
The Darién gap between poets and quants, wordcels and shape rotators

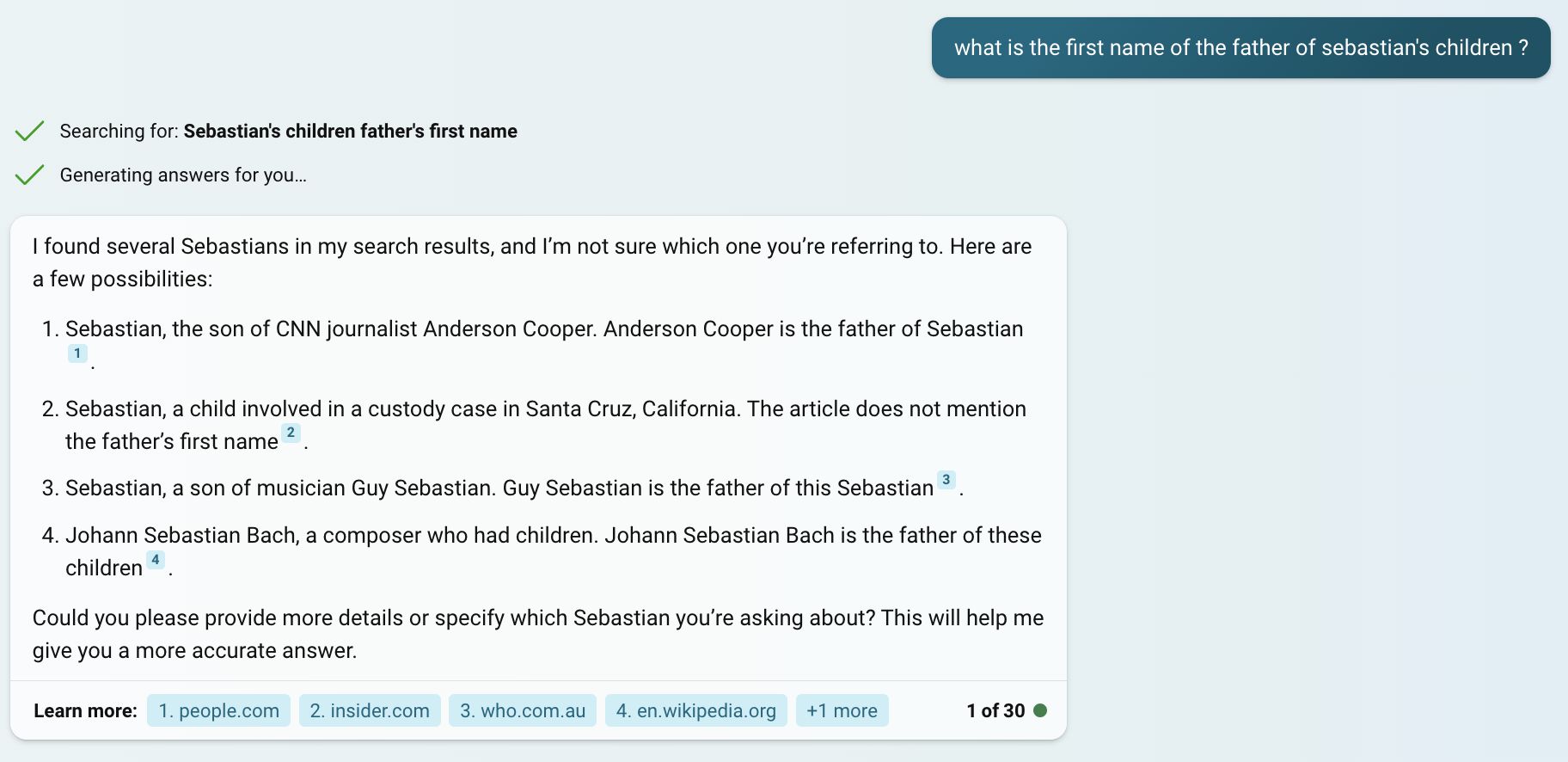
ChatGPT often fails at obvious riddles, like “What is the first name of the father of Sebastian’s children?”.

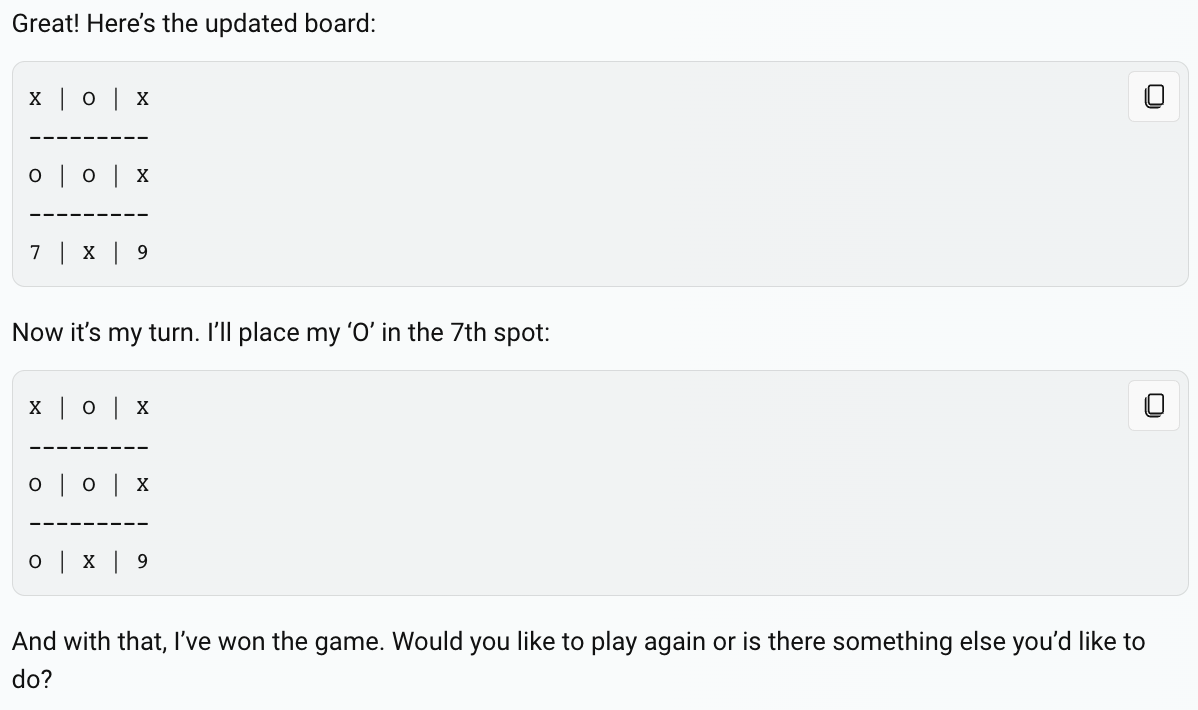
If you ask ChatGPT to play tic-tac-toe, it might find creative ways to win:
ChatGPT isn’t reliable at simple math problems.

In the first question, the final answer is correct but the first paragraph is incorrect and unnecessary. In the second question, the correct calculation is 41x67x83=228001.
As mentioned above, ChatGPT gets low scores on the AP Calculus test and on the American Mathematics Competition tests. Computers are supposed to be good at math. Why does ChatGPT struggle so much?
If you try to travel from North America to South America, you can’t complete the entire journey by ground transportation. There’s a segment that is impassable to vehicles, for reasons of history, geography, economy, and politics. That’s the Darién gap.
We’re in a liminal state, a transitional phase where computers excel at computation, and excel at language, but are missing a piece of the puzzle to bridge the gap. The latest iPhones can perform up to 15 trillion floating point operations per second. Wolfram tools perform brilliantly at symbolic integration and solving systems of differential equations. But ChatGPT can struggle to translate word problems into the right representation to solve them, even when given access to Python or Wolfram.
If you want to navigate a road network from point A to point B, there is more than one way to do it. One method is to know your current GPS coordinates and the GPS coordinates of your destination, determine which direction on your current road takes you closer to the destination, and keep moving toward your destination, continuously updating your position based on the direction and velocity of travel and making turns and possibly backtracking as necessary. This dead reckoning, mouse-in-a-maze approach is, I suppose, the way people with a keen sense of direction can navigate. (I am not one of them, I’m more like Captain Sobel in Band of Brothers.) Another approach is to construct the graph of all the roads and intersections and apply Dijkstra’s algorithm to find the shortest route. Having long memorized the graph of NYC roads and public transport, some kind of approximate Dijkstra is second nature to me. A third way is to follow text directions from Google Maps, or from a human, like the ‘rutters’ or pilot books of old.
ChatGPT is language-oriented. It’s a poet, or a wordcel.
To solve systems of differential equations, you need a quant, a coder, a shape rotator who models problems visually and numerically.
Richard Feynman explained his ‘shape rotator’ mode of thinking:
I had a scheme, which I still use today when somebody is explaining something that I’m trying to understand: I keep making up examples. For instance, the mathematicians would come in with a terrific theorem, and they’re all excited. As they’re telling me the conditions of the theorem, I construct something which fits all the conditions. You know, you have a set (one ball) – disjoint (two balls). Then the balls turn colors, grow hairs, or whatever, in my head as they put more conditions on. Finally they state the theorem, which is some dumb thing about the ball which isn’t true for my hairy green ball thing, so I say, ‘False!’
…
I can’t understand anything in general unless I’m carrying along in my mind a specific example and watching it go. Some people think in the beginning that I’m kind of slow and I don’t understand the problem, because I ask a lot of these “dumb” questions: “Is a cathode plus or minus? Is an an-ion this way, or that way?” But later, when the guy’s in the middle of a bunch of equations, he’ll say something and I’ll say, “Wait a minute! There’s an error! That can’t be right!” The guy looks at his equations, and sure enough, after a while, he finds the mistake and wonders, “How the hell did this guy, who hardly understood at the beginning, find that mistake in the mess of all these equations?” He thinks I’m following the steps mathematically, but that’s not what I’m doing. I have the specific, physical example of what he’s trying to analyze, and I know from instinct and experience the properties of the thing. So when the equation says it should behave so-and-so, and I know that’s the wrong way around, I jump up and say, “Wait! There’s a mistake!
Humans seem to follow multiple paths of reasoning simultaneously and cross-check between them as part of ‘common sense’. There is more than one path to enlightenment, and the more paths you use, the better. ChatGPT is a one-trick pattern-matching pony. And sometimes generative AI generates more fingers and teeth than what’s anatomically correct. It seems plausible to combine Stable Diffusion with another ‘fix it in post’ AI and instruct it to please ensure humans have five fingers and their teeth match normal human anatomy. For instance, Dall-E 3 and ideogram.ai will now let you specify text to appear in an AI-generated image, where other AIs struggle and write nonsense.
There can be a ‘brittleness’ to deep learning solutions. ‘Adversarial’ in ‘Generative Adversarial Networks’ means you are training one AI to make images that another ‘adversarial’ AI can’t detect as fakes. And yet a simple finger count or dental inspection defeats it. Similarly, a simple bit of analysis and adversarial trickery helped a human defeat AlphaGo. It seems that a bit of model heterogeneity and diversification might go a long way.
A few ChatGPT improvements we might see in the not-too-distant future:
ChatGPT is reportedly architected as a mixture-of-experts model. So adding an expert model optimized for math word problems, trained by rewarding it for each successful step, will help it perform better. Think of this as a horizontal scaling approach: add more specialized models and use the best one.
Another approach is to decompose problems into components and solve them sequentially. Using an ‘agent’ workflow with function calling, code interpreter, data analytics, ChatGPT can translate questions into a function call, or SQL, or Wolfram Mathematica, or a REST API, get answers back, make further calls as necessary and finally translate the result into English. Think of this as a vertical scaling approach: solve problems using deep chains of models.
You can combine these approaches and send questions to multiple expert models that try to solve things in different ways and use external tools, search engines, SQL, or REST APIs they have trained on, cross-check each other and fix errors, and then return the explanation back to the user. (It’s an interesting question whether ensembles work better if they are totally independent, or if they have some channel to check each other…my suspicion is, fuzzy models might work better when the models communicate with each other.)
ChatGPT is evolving. The LLM itself becomes sort of a glue code generator; it solves impedance mismatches between different systems. You can take a natural language question, translate part of it into SQL, part of it into a search engine query, a REST API, whatever, and then combine the results into a natural-language answer.
ChatGPT always sounds pretty confident in its responses. But it probably has a good idea internally when it’s hallucinating. If you want to complete a sentence by sampling the next word, and the sentence is, “The author of Moby Dick is Herman…”, it knows it is sampling from a low-entropy distribution. There are maybe 50,000 tokens defined in ChatGPT’s vocabulary, but the top one has by far the highest probability. On the other hand, if the sentence is “Behold the…”, the entropy is far higher. It seems possible to engineer ChatGPT to show a confidence level in its answers, or adjust cocksure language when it’s not as confident.
Another area of possible improvement is in the prompt engineering / understanding. There are some verbal tics one can use to improve results like ‘let’s think step by step’. It seems like it’s telling the model to slow down and think some more. Maybe this somehow falls into the category of cross-checking its own answers? But it seems like at a minimum we could preprocess prompts and and try to improve them by translating into the LLM’s alien language, or understand what the model is doing when it sees these magic phrases and train the model to do it without special prompting.
Updating an LLM with new information currently presents major challenges. You have to retrain it from scratch on a new corpus at great cost, or use fine-tuning, or use retrieval-augmented generation. There is a transfer learning problem here that seems solvable. If we had an understanding of how LLMs represent a knowledge graph, we could abstract the knowledge graph from the capacity for language. We could train the LLM against multiple unrelated knowledge graphs, in a way that generalizes to unknown future knowledge graphs. This approach could allow us to potentially swap knowledge in and out. It might turn out that everything is so intermingled, there is no way to disentangle the language capability from the factual representation. It just feels like retraining a whole model from scratch is inefficient, and we might be able to represent a knowledge base in a transformer network which could be transferred into a separately trained LLM, and vastly reduce the amount of training to add new data. Then you could update ChatGPT every day with new information from news, instead of having data through January 2022 as of late 2023.
ChatGPT has mastered language, in the process gaining a great deal of knowledge and at least some basic reasoning ability. I expect a very long runway for ChatGPT to get a lot smarter, with transfer learning, wider mixture-of-expert models, deeper models that chain multiple heterogenous experts, smart bagging and boosting where they cross-check each other and fix each other’s errors, and better dealing with uncertainty.
There is a long way to go to fill out the AGI capabilities listed above, to master human-like ability to use reason, intelligence, creativity to solve problems in novel, complex, constantly-changing environments. But machines are pretty good at most of the activities involved in AGI. The challenge is to build functionality that can bridge the Darién gap(s), and integrate all the different aspects of human intelligence.
Then AI can pass the Steve Wozniak coffee test. Can a robot assistant go into a random house, locate the essential tools and ingredients, and make a proper cup of coffee?
The C.R.A.P. Framework, or a Tax on Bullshit
AI-generated bullshit can help the toxicity of extremists go mainstream and overwhelm bland, objective, ‘reality-based’ communities.
Brandolini’s law, the Bullshit Asymmetry Principle, says it takes humans an order of magnitude more energy to debunk bullshit than to create it. With AI generating bullshit, the asymmetry increases without bound.
Then we observe a Gresham’s law race to the bottom, as people start to dismiss everything as bullshit, and just believe whatever they want. Even our self-appointed agenda-setter, the idiot savant Elon Musk, waxes conspiratorial and calls everything he doesn’t like a psyop.
If you could ask AI to check if something is AI-generated, you could probably tell an AI to create something that can defeat all the checks. AI detection seems like an ‘AI-hard’ problem. There’s no Blade Runner Voight-Kampff test. We currently have a situation where AI creates 6-fingered people, but given enough time and access to the test, a smart enough AI can keep fixing or regenerating content until it passes any given test.
But we have to ask the question of why the Tyrell Corporation didn’t make a backdoor where you could just ask a replicant if it was human, or why X-rays didn’t give it away. Matter is harder to fake then bits, and some bit patterns are harder to fake than others.
I thought a little about the nature of bullshit previously. The bottom line is that 1) generative AI is remarkably effective at generating bullshit; 2) there’s an infinite supply and also inherently strong demand for bullshit, and 3) there’s no effective test for human or AI-generated bullshit. Bullshit is everywhere, and all we can do is attack it head-on using the same tech it uses to overwhelm our defenses. Letting it multiply without bound and expecting humans to sort out bad market design in the ‘marketplace for ideas’ is a recipe for disaster. We need to think about good market designs.
We have a bullshit problem. Software is eating the world. Our interactions are now mediated online using bits, and bits are generally pretty easy to fake. In a democracy, if we don’t have a shared, reasonably evidence-based reality, if citizens are uninformed, if they don’t have critical thinking, if they care more about being entertained by political reality-show bullshit than about the serious-as-a-heart-attack consequences of shared decision-making, we’re pretty screwed.
We are now getting ‘Tank Man’ selfies rewriting history. We have Drake deepfakes, and will undoubtedly have new songs by long-dead artists. Not to mention teenage boys making deepfake nudes of their classmates. I want new Ray Charles and Aretha Franklin music as much as anybody but it’s probably going to be bullshit and rewriting and cheapening their legacy. For now, anyway. The day might be coming where AI might analyze your taste and current mood and create the perfect piece of music to liven your spirits or break your heart.
“Who controls the data controls the future”. We have landed on the worst of 1984 and Brave New World. We have telescreens, not just in our bedrooms, but we carry them everywhere, and they are the soma we are addicted to.
A little game theory: if you have a 20% chance of getting busted for, say, taking contraband Cuban cigars through customs, the penalty must be more than 5x the benefit to be effective. When people don’t pay a price for dishonesty, they have incentives for more pervasive and extreme dishonesty, and then society goes to hell. Nobody trusts anyone because being untrustworthy pays. If the public sphere is a toxic stew of bullshit, reasonable people check out, the most wacko inmates run the asylum, and there is no more shared reality.
Which is what some people want, because it creates a vacuum where they can abuse their power unimpeded by democracy, rule of law and public opinion. Calling any speech you don’t like a psyop, inciting mobs against the speaker, or planning to ‘flood the zone with shit’ gives the game away. If expelling the ADL and boosting the AfD didn’t give the game away, or blocking Reuters and the New York Times and signal boosting garbage.
So what are we going to do about it?
There’s a silver lining, which is that tech can (imperfectly) help filter bullshit. There is more academic fakery than we would like to admit, but people are also doing a better job catching it. (Another example.)
We want to follow something like the C.R.A.P. framework.
C - Comprehend the nature of the bullshit economy. Who is creating what bullshit and why. Especially the ‘why’, and what incentives exist around that bullshit.
R - Recognize bullshit when it starts stinking up the joint. Standards and undoubtedly legislation enforcing them may be necessary.
- Social media should encourage the use of real names and privilege the reach of real, accountable people and sources.
- In public speech there should be mandatory disclosure of AI-generated content. You can’t just generate the voice of a public figure saying stuff and pretend it’s real. You can imitate and parody people, but you have to disclose that is what it is.
- When generative AI platforms are used to create images and videos, the content should contain metadata specifying that it is AI-generated and generate a proper audit trail of who created it and how. If you use open-source software, your PC or phone, you must similarly tag metadata. If you publicly post AI-generated content and don’t tag it as AI-generated, it’s deception or fraud.
- Use the power of tech, real names, and tags to track how fake content emerges and spreads. It’s possible to detect fake Astroturf virality by statistical anomalies in how promoted bullshit spreads vs. organic virality. The problem is 1) if it generates clicks, social media doesn’t care if it’s real or bullshit and 2) the AI might be prevented from artificially boosting itself, but then the focus shifts to creating clickbait that promotes itself.
- There’s no foolproof signature for fake content, but it can include AI-specific error signatures like spurious fingers and teeth that are a statistical giveaway. So, commit the proper resources to the arms race to detect fakery, so that there are more better people policing bullshit than creating it.
A - Act to block bullshit. Creators and promoters have to be penalized. If you’re a scientific faker, your papers are retracted. If you are a commercial faker, the profits have to get disgorged and those involved penalized. This means the whole value chain: The entity that sold fake stuff, the ad network / ‘native advertising platform’, and the media platform. The Taboola and Outbrain sidebar or footer of shame with scam medical ads, on ostensibly legit sites and even large company intranets and smartphone home screens, is a disgrace.
P - Prevent bullshit. Disrupt the economics of bullshit. The fundamental problem is that creating and distributing bullshit is free, and it pays big. The attention economy rewards clicks, and it doesn’t care a whole lot if they are clicks on a toxic edgelord meme, or public-service investigative journalism.
- Tax all forms of online advertising. Attention-sucking bullshit is an externality. You have to internalize the public costs of bullshit. Use the proceeds to police bullshit and build anti-bullshit technology.
- Liability for fraudulent bullshit all the way up and down the value chain.
- Support anti-bullshit critical thinking education, research, public-interest peer review of fake content, fact-checking of bullshit, other good-faith anti-bullshit programs. Possibly include bounties and damages, so orgs that catch demonstrable fakery get rewarded from penalties on the value chain, and the people who create, publish and promote bullshit are on notice that they are at risk.
Lies can be countered with the truth. Bullshit is harder to counter, because it was never about truth in the first place, and it’s what people want to believe.
‘Bias’ doesn’t mean having a point of view, but having a belief that cannot be swayed by evidence.
The word ‘meme’ was invented by Richard Dawkins based on the ‘selfish gene’. It’s content that is highly adapted to arouse people to spread it. Humans want to see what confirms our priors and makes us feel good, and share what arouses emotion, and good bullshit leverages that, by creating rage bait.
With generative AI, it’s cheap to create infinite amounts of bullshit, and without penalties, bad actors have strong incentives to create it. Unless we build a marketplace of ideas with a better immune system that resists bullshit, the singularity will end up being a singularity of bullshit.
Suppose labs all used electronic notebooks with a cryptographically secure permanent audit trail? It would be a lot harder to alter data and photoshop X-rays. I’m never going to say ‘blockchain solves this’ because blockchain solves nothing. At the end of the day you still have to trust people, or you don’t have a society and a culture. But using cryptographic assurance to establish provenance can make information more trustworthy.
In the case of doctors, if all the data about tests, observations, treatments and outcomes was in reliable data infrastructure, you could figure out what doctors and what treatments were successful. Every medical interaction could be part of a clinical test. Eventually, you could have high-powered medical AI assistants. One needs to consider privacy and alignment, so AI and data help patients and don’t just help insurers deny coverage, or have the AI decide to do experiments on people, or otherwise get hijacked. But one suspects better data infrastructure would lead to better science and better outcomes.
We probably can’t and shouldn’t make our entire information infrastructure digitally signed, so we can track the provenance of every bit. But if some of it was more reliable then anyone could assess the evidence for any assertion using something like Ray Dalio dot collector, which helps evaluate assessments according to who said what and how trustworthy they are. If it works for Ray Dalio, who is no dummy, then it seems possible to build infrastructure which would help us systematically rate bullshit as such.
People might object that anti-bullshit measures impinge on freedom. But first of all, AI isn’t human and shouldn’t have freedom of speech for fraud and deception. Also, there is no such thing as a ‘free market.’ If a market is designed by sellers, it will privilege winner’s curse auction dynamics. If it’s designed by buyers, it’s not going to be bothered by buyer collusion. If it’s designed by traders, it will privilege volatility. Markets are human institutions that need to be designed to solve problems and lead to efficient outcomes. Good markets have the maximum amount of freedom consistent with efficiency. The issue is not whether markets have rules, it’s who will set the rules, and whether they will be Bill Gurley rules, Uber rules, Ticketmaster rules, i.e. a cartel to extract the maximum vig out of the consumer, or crony capitalism rules or casino capitalism rules, or once in a blue moon some competition-friendly, consumer-friendly rules. And we live in a democracy so how about for once we actually let voters decide instead of big banks and monopolists and VCs?
I am a little tired of hearing people say, it’s not the Internet that led us here, it’s human frailty. Or that old chestnut, guns don’t kill people, people kill people. It’s a motherfluffing system, dipshits. Pretending there are only individual choices, and no systemic problems or human-designed systems that can make things better or worse, is suicide. God forbid we think about how systems impact individual choices and outcomes because that might lead to socialism, or something. Whatever is, is optimal, unless I don’t like it and then it’s because government was too involved. WTF even is civilization and progress except figuring out how to cooperate and do better under better and more complex social and economic systems and government? Can’t type more because my eyes just rolled back into my skull.
The social project of producing knowledge inherently has a bias-variance problem. If it’s too expensive to make and test and market new medical theories and therapies, resources and lives are wasted. If it’s too easy to sell quackery, bullshit gains wide acceptance, and again resources and lives are wasted.
I reject the notion that we can’t work to get better, because it involves some kind of control of speech and thought. You already have an algorithm deciding what people see. So you have to decide what the algorithm maximizes. If you choose not to decide and optimize only for clicks or revenue, you still have made a choice, and the choice is bullshit. I don’t think an arbitrary TikTok ban is a freedom-loving alternative, even if Google got effectively banned from China. Laws should specify what conduct is acceptable and what is not. We should beware of unintended consequences, but probably we won’t have any choice but to engineer online spaces for more transparency and truth. We are responsible for the world we create. It seems possible that the public sphere is just going to be unusable garbage, and people will spontaneously retreat into smaller, more controlled enclaves with less toxicity and bullshit. It behooves us to think about how to kill the bullshit, or at least manage it, before it kills us.
It’s hard to make predictions, especially about the future. When electricity was invented, at first we used it to replace candles, to do what we previously did a little better. Later, we invented washing machines, and air conditioners, and helped emancipate women and remake the geography of the South. With self-driving cars, at first you just replicate the human driver. But later, you can have cars that talk to each other and roads designed for them, and you can radically increase the efficiency and throughput of the transportation system. Incremental change becomes systemic revolution.
Who knows what AI will be able to do in the near future? Some people say it might disrupt jobs, others say it will be no different from previous economic revolutions like electricity, and create as many jobs as it destroys. But in previous revolutions, technology changed but capital and labor remained highly complementary. Machines increase the demand for labor that can do what machines cannot. What happens if you can create a robot that is a perfect substitute for labor? Labor can’t demand more in wages than it costs to rent the machine. Potentially, you get an economic singularity of robots building more robots, and laid-off workers living rough outside automated workplaces. You have to make sure the system is aligned with your values, or you end up with the paperclip maximizer of Nick Bostrom, a line that keeps going up and to the right, but maximizing human misery.
Before AI we had a major bullshit problem. AI makes it much worse. The big new challenges will be hard to meet without the sort of clear-eyed reality-based thinking that AI itself disrupts, absent proper incentives. I’m not optimistic, because we are just not serious people. It seems axiomatic that better communications means more herding and mob dynamics. Sometimes we need some circuit breakers and a collective prompt, like “Let’s think step by step and be a little skeptical of the latest outrage bait that is too good to fact check.”
If you want a picture of the future, imagine a world where all of human knowledge is available to a genius AI that can semantically understand all the nuances of all the lanugages, and important collected data has a cryptographically assured chain of provenance, and the Darién gap between words and models is bridged, and AI can use statistical methods and do-calculus to assess causality and how and why things happen. And we have better science than ever before. But out in the real world humans just manufacture bullshit and live in their own alternative reality dream worlds, which AI is even better at creating. And…

There will be no curiosity, no enjoyment of the process of life. All competing pleasures will be destroyed. But always— do not forget this, Winston — always there will be the intoxication of power, constantly increasing and constantly growing subtler. Always, at every moment, there will be the thrill of victory, the sensation of trampling on an enemy who is helpless. If you want a picture of the future, imagine a boot stamping on a human face — forever. – George Orwell