16 Agent Patterns: An Agent Engineering Primer

Any sufficiently advanced technology is indistinguishable from magic. — Arthur C. Clarke
What are AI agents? Simon Willison crowdsourced a lot of definitions that focus on:
1) Using AI to take action on the user’s behalf in the real world (i.e. what the agent does)
2) Using AI to control a loop or complex flow (i.e. how the agent does it).An AI agent takes a sequence of actions based on an AI-determined control flow.
Agents use prompts as the CPU of a Turing machine that can manage state, memory, I/O, and control flow. The agent can access the Internet and tools to perform compute tasks, retrieve info, take actions via APIs, and use the outputs to determine next steps in a loop or complex control flow. Maybe even control a browser or computer.
In this post, we’ll try to develop a roadmap of agent concepts and patterns to learn, and resources to learn them.
Spinning Up: From Prompting to Single-Turn Agents
Before diving into agent patterns, let’s review 4 LLM foundational skills:
- Prompting – The term ‘Prompt engineering’ contains an element of puffery, but we need to give clear, specific, instructions, so the LLM answers properly and in the right format. It’s an entry‑level skill that underpins every other pattern.
- C-L-E-A-R Framework:
- Contextualize - Specify a role or persona and intent: “You are a copy editor with years of experience polishing articles and blog posts for web publication. You will read the content carefully and suggest changes for clarity, style, and standard usage.”
- Limits - Length; format e.g. ‘three bullet points’; tone or style e.g. ‘concisely’, or ‘like a tech journalist’, or ‘only use facts from this text’.
- Elaborate and give Examples - Explain and provide as many details and specifics as possible. Use chain of thought and other advanced prompting methods.
- Audience - Identify the audience the response is addressed to, such as ‘explain like I’m 5’.
- Reflect or Review - Prompt ChatGPT to ask clarifying questions before answering, give itself space, such as “think step by step”, “make sure of x before answering”.
- Alternatives: T-C-E-P-F-T (Task, Context, Example, Persona, Format, Tone). Or P-R-E-P-A-R-E-D (Propose, Role, Explain/Explicit, Presentation, Ask, Rate/Reflect, Emotions, Diversity). Use what resonates with you.
- These days, you don’t need to spend hundreds of hours learning prompt engineering. Think about your intention, take a first crack using one of the above frameworks, and then ask your favorite LLM to improve it, iterating as necessary. OpenAI Cookbook: Enhance your prompts with meta prompting.
- Side quest - proper evals, and automated prompt engineering with tools like DSPy. If you have good evals, you will eventually have good prompts and outputs through iteration. If you don’t have good evals, changes in underlying LLMs and assumptions will break your prompts and workflows.
- As prompts become more dynamic and complex and we add tool use (discussed next), we start to think about it as ‘Context engineering’ to ensure the LLM has info it needs to provide a good answer. However we name it, good prompting and evals are a foundational skill. You need to know how to talk to the AI and measure the results.
- See previous post: Practical ChatGPT Prompting: 15 Patterns to Improve Your Prompts
- Also see GPT 4.1 prompting guide. The recent 4.1 OpenAI models are trained for agentic workflows, they do many things automatically that required complex prompting in previous models.
- C-L-E-A-R Framework:
-
Tool Use – Expose a catalog of external APIs to the agent, like a Python function, search, SQL, REST, a browser, a full Python interpreter REPL, or a shell terminal, etc. Let the LLM decide whether to call a tool and which tool to call at each turn of the conversation. The LLM can respond with a request to call a tool using a provided calling signature; the user or client calls the tool and responds with the output; the LLM then uses tool output to determine the final answer or an additional tool call). See Microsoft: Tool Use Design Pattern
-
Retrieval-Augmented Generation (RAG): Give the agent documents and a tool (such as a vector database) to find relevant parts of the documents and respond using them via in-context learning, i.e. stuffing the prompt with data to ground the answers. “Please answer this question using the following text”. See Retrieval Augmented Generation (RAG) — A quick and comprehensive introduction.
- Chain‑of‑Thought Prompting – Ask for step‑by‑step reasoning traces that make the model’s logic explicit and usually boost accuracy on math, logic and multi‑step tasks. “Before providing a final answer, please think step by step, walk through your complete research and thought process, and show your reasoning.” Kind of like ‘explaining your code to your rubber duck’, telling the model to show its work, and explain what it’s doing as it does it, forces it to think longer, and improves performance. Thought traces are also important for agents to remember what they did previously and why they did it. Paper: Wei et al.
With these 4 elements you can build highly capable single-turn OpenAI Assistants or Custom GPTs.
You can write a system prompt that describes a workflow to follow in response to user input, give it docs with detailed processes and reference information, and external tools to use. See for instance this Tuck AI Matrix custom GPT, which follows a proprietary methodology to do basic evaluations of M&A deals.
However, the OpenAI custom GPTs and Assistants (and their equivalents on other platforms) have a single prompt, so they aren’t true multi-turn agentic workflows. (They can call multiple tools though.) To level up to full-blown agentic workflows, we want more customizable multi-turn workflows that may use many different models, custom tools, sub-agents, and complex control flows.
16 Multi-turn Agent Patterns
-
ReAct (Reason + Act) Loops – Interleave “Thought → Action → Observation” so the agent both reasons and calls tools (search, code, DB) in the same dialog, allowing complex chains of thoughts and actions. This was the breakthrough behind AutoGPT, which you can run online here. Ask a question like ‘Find the best coffee grinder for espresso under $300’, and it will loop through a process of thinking, what are the tasks I need to do based on what I’ve done so far, what is the highest priority task, do it, observe the output, iterate until the goal is reached. Paper: Yao et al. ; Blog posts: Matt Webb; Simon Willison
The ReAct pattern is fascinating and powerful, but the autonomy can make it unpredictable and hard to reason about, which is a general tradeoff when building agents. The more autonomy you give it, the more room for emergent behavior, but also the more risk it goes off the rails. -
Prompt Chaining & Sequential Workflows – Break a complex task into ordered sub‑prompts with intermediate validation (“gate checks”) before moving to the next stage. LangChain: Build an Agent. Example: a news gathering workflow. Small prompts that perform composable tasks that can be tested and optimized independently are more predictable and easier to maintain than long ‘God’ prompts that try to do everything. See What We’ve Learned From A Year of Building with LLMs
-
Structured Output – Since errors tend to compound as you go down the agent’s trajectory, structured outputs and validation are critical. Ask the model to return JSON, then validate it, letting downstream code parse or act on the response safely. If output doesn’t validate, attempt to fix the output, or fix the input and retry. The GPT-4.1 models are exceptionally good at returning valid JSON, which you can also use Pydantic to specify and validate. Study the prompting guide thoroughly.
-
Human-in-the-loop – At the current maturity of AI development, fully autonomous agents are typically very challenging to achieve in complex, high-stakes environments, where they add the most value. It’s much more realistic to try to make agentic assistants and copilots that take humans through a structured process, than to aim for full autonomy. The AI can speed things up dramatically, but performance can also be hit-or-miss, so human supervision is critical. At key steps the human should evaluate and course-correct as necessary. Time travel allowing the human to go back to a previous step, adjust, and try again can also be useful.
In fact, if you remember nothing else from this post:
🤖🦾 Use AI for what AI is good at: parsing lots of information quickly and generating a first draft at a near-human level; fuzzy logic (easier to ask the LLM the human name for a URL than to parse the numerous ways websites provide titles)
🛠️⚙️ - Use tools for what tools are good at: faithfully executing algorithmic workflows;
👩⚕️💪 - Use humans in the loop for what humans are good at: critical thinking and creativity.
-
Reflection – After an initial answer, the agent critiques its own work and revises. For instance, a check for factuality may reduce hallucinations. Is this summary consistent with the text it summarizes? The agent can reflect and improve multiple times until satisfied, and/or perform multiple separate checks, like for factuality and also a Flesch-Kincaid readability benchmark. See DeepLearning.ai “Reflection” pattern. Paper: Shinn et al.
-
Evaluator‑Optimizer (Generator‑Critic) Loops – Divides the reflection pattern into substeps. One LLM prompt proposes an answer, another scores/criticizes it, and also provides directions for improvement; apply recommended improvements; and iterate until no further improvements are needed. Anthropic post “Building Effective AI Agents”
-
Task Routing / Mixture‑of‑Experts – A router runs a classification prompt based on the current state to determine the next action, such as a prompt or sub-agent workflow. Anthropic Agentic Systems - #2. Routing
-
Agentic RAG & Specialized Retrieval Teams – Multiple retrieval agents individually query their own knowledge pool; an aggregator agent synthesizes the evidence before final generation. IBM primer “What is Agentic RAG?”
-
Memory – In the basic ReAct workflow, the previous chain of the conversation serves as the record of everything learned so far. But you might want to structure the memory in the agent in a more efficient manner, and inject knowledge into the context in the manner the LLM can use it most effectively. See e.g. IBM: What is AI agent memory? ; Mem0
-
Short‑Term Memory – Keep just enough context (conversation buffer, sliding window, or summary) inside the model’s token limit for coherent multi‑turn chats. Context Windows: The Short‑Term Memory of LLMs
-
Long‑Term Memory – Persist facts or conversation extracts or summaries in a vector database, knowledge graph, SQL or NoSQL database, and retrieve them on demand so the agent “remembers” over the course of a long session working with lots of information, and across sessions. (A vector database has one job, fast nearest neighbors so you can look up text by semantic similarity.) Pinecone guide to conversational memory with LangChain
-
-
Plan‑and‑Execute (Hierarchical Planning) – First draft a high‑level plan, then execute each sub‑task in order. LangChain: Plan-and-Execute Agents; Paper: Wang et al.
-
Parallelization of Sub‑tasks – In contrast to sequential tasks, we can fan out independent LLM calls asynchronously (map‑reduce, parallel tools) and aggregate results for speed or consensus. We can perform similar tasks in different ways and pick the best one, or take all the outputs and synthesize a response from them. With ‘mini’ and ‘flash’ models (or local models), it can be cheap, fast and efficient to send hundreds of queries over a data set to process each one individually and simultaneously. LangChain: How to invoke runnables in parallel
-
Tree of Thoughts – Many agents run variations on search processes. The agent can explore multiple possible paths of thinking, decisions, or hypotheses before settling on an output or an action. Agents can go beyond single-step or linear reasoning by allowing branching and revisiting of different trajectories. See papers: Tree of Thoughts (ToT) and Graph of Thought (GoT)
-
Guardrails – Users may try to ‘jailbreak’ an app to use it in unexpected ways, and agentic processes can go off the rails and attempt costly or embarrassing or even dangerous actions. Guardrails. a form of reflection, can allow you to assert that the agent is on track at each step, and correct, or stop, or prompt the human if it strays.
-
Orchestrator‑Worker Architecture – A central orchestrator maintains state, assigns work to specialized worker agents, and merges their outputs—a pragmatic bridge to complex multi‑agent systems. The LangGraph state graph framework is one pattern. The state graph paradigm provides transparency, maps well to structured processes with time travel, and potentially in the future to low-code frameworks and cloud deployment.
Alternatively, we can use the OpenAI Agents toolkit, make each sub-agent node a tool, and have a top-level reasoning prompt describing a workflow and telling the LLM to run the workflow using the available tools.
You can also use low-code frameworks like Zapier, Make.com, n8n, and Automation Anywhere (and a ton of others), which could then call an AI prompt to make control flow branching decisions, run loops, call OpenAI Assistants or agents deployed in the cloud. -
Multi‑Agent Collaboration – An orchestration pattern that uses distinct role‑based agents (e.g., Planner, Coder, Tester) that converse to solve problems that exceed a single model’s capacity, in a peer or hierarchical organizational structure. Multi-agent systems can be a bit like using Docker/Kubernetes microservices vs. monolithic architectures. They can provide a helpful decomposition, or make the system more complex and harder to reason about. For my money, you can get a lot of mileage with AI in a structured workflow running in LangGraph, n8n, Zapier, etc. In general I would recommend starting with simple chained pipelines, over complex multi-agent solutions. AutoGen is a leading multi-agent framework. Wired article.
-
Model Context Protocol and other communications protocols – When you create a tool, after implementing its functionality, you have to tell the LLM how to use it: the input schema, the output schema, when and why to use it. Model Context Protocol (MCP) is a standard for doing this.
Another important evolving standard is Agent2Agent protocol (A2A). If one agent calls another agent, it may be a long-running process and a multi-turn chat conversation, unlike the REST call typically described by MCP. So there may be a need for a different standard to monitor long-running processes that come back to ask for more information, or that you want to send a sequence of interactive requests to. See the paper: A Survey of AI Agent Protocols
Where To Start
If you want to start building an agent to automate your pain points, here are some ways to start:
- Connect Zapier to your SaaS services and LLM, like write a mail autoresponder that applies a prompt to extract stuff from an email and updates the CRM.
- If you are enterprise as opposed to SMB, and putting credentials to all your SaaS in Zapier gives your the heebie-jeebies, use n8n on-prem instead. (Or standardize on an on-prem or cloud no-code framework, of which there are many.)
- Write or grab some MCP wrappers (here is a list, or check out Jeff Emanuel’s ultimate MCP server with connections to tons of services), connect them in the Claude desktop client, and ask Claude to do stuff in your favorite services.
- For the most advanced custom agent workflows, LangChain and LangGraph are great to get a POC up and running. If I want to figure out how to build an LLM workflow, typically I’ll look up how LangChain does it and try their variations, different LLMs and prompts, and take it from there. LangChain can be frustratingly complex and beta. Sometimes you realize all the magic is in the prompt and you can just write directly to e.g. OpenAI. They try to do all things for all people and have the most comprehensive ecosystem. But they can be architecture astronauts and try to do too much, make a lot of breaking changes, docs are not always great. OpenAI Agents SDK, CrewAI, AutoGen, LlamaIndex, SmolAgents are other alternatives.
- Don’t be afraid to do things that need a lot of sequential prompts or to send a lot of prompts in parallel asynchronously. It’s hard to do things well with one prompt, our job is to make a reliable agent from unreliable LLM calls.
Final Thoughts
The era of agents is here. If you can explain a process in plain English, you can probably find or build MCP servers around the tools it uses, and build an agent to take a crack at it. If it’s a simple process, you might be able to fully automate it most of the time; if it’s a more complex process, you might be able to build a structured human-in-the-loop process around it that will level up productivity.
When you see an agent doing something simple, like my daily AI news bot, or something magical, like OpenAI’s Deep Research, it’s probably doing something that is a composition of patterns like these, and the right prompts applied to the right contexts. If you’ve read this far, you have an initial grasp of the basic concepts of agent engineering, and a few places to continue your learning journey!
Further Reading:
- Anthropic: Building effective agents
- Anthropic: How we built our multi-agent research system
- LangChain: Workflows and Agents
- Anthropic: Our framework for developing safe and trustworthy agents
- Chip Huyen on Agents
- Andrew Ng: The Batch
- DeepLearning.ai
- Mastering AI Agents: The 10 Best Free Courses, Tutorials & Learning Tools
- A Survey of Agentic AI, Multi-Agent Systems, and Multimodal Frameworks Architectures, Applications, and Future Directions
- Agent Frameworks
- LangGraph
- OpenAI Agents SDK
- Google ADK
- LlamaIndex
- AutoGen / AG2 (confusing fork under way)
- CrewAI
- SmolAgents are other alternatives.
- Druce’s related stuff
- A slide presentation
- I save articles here
- Skynet and Chill daily AI reading (agent-generated with HITL)
- AInewsbot agent to write an automated daily news letter. Barely agentic, it’s a long chain of prompts, the AI chooses stories and summarizes them and writes clever titles but not a complex AI-driven control flow.

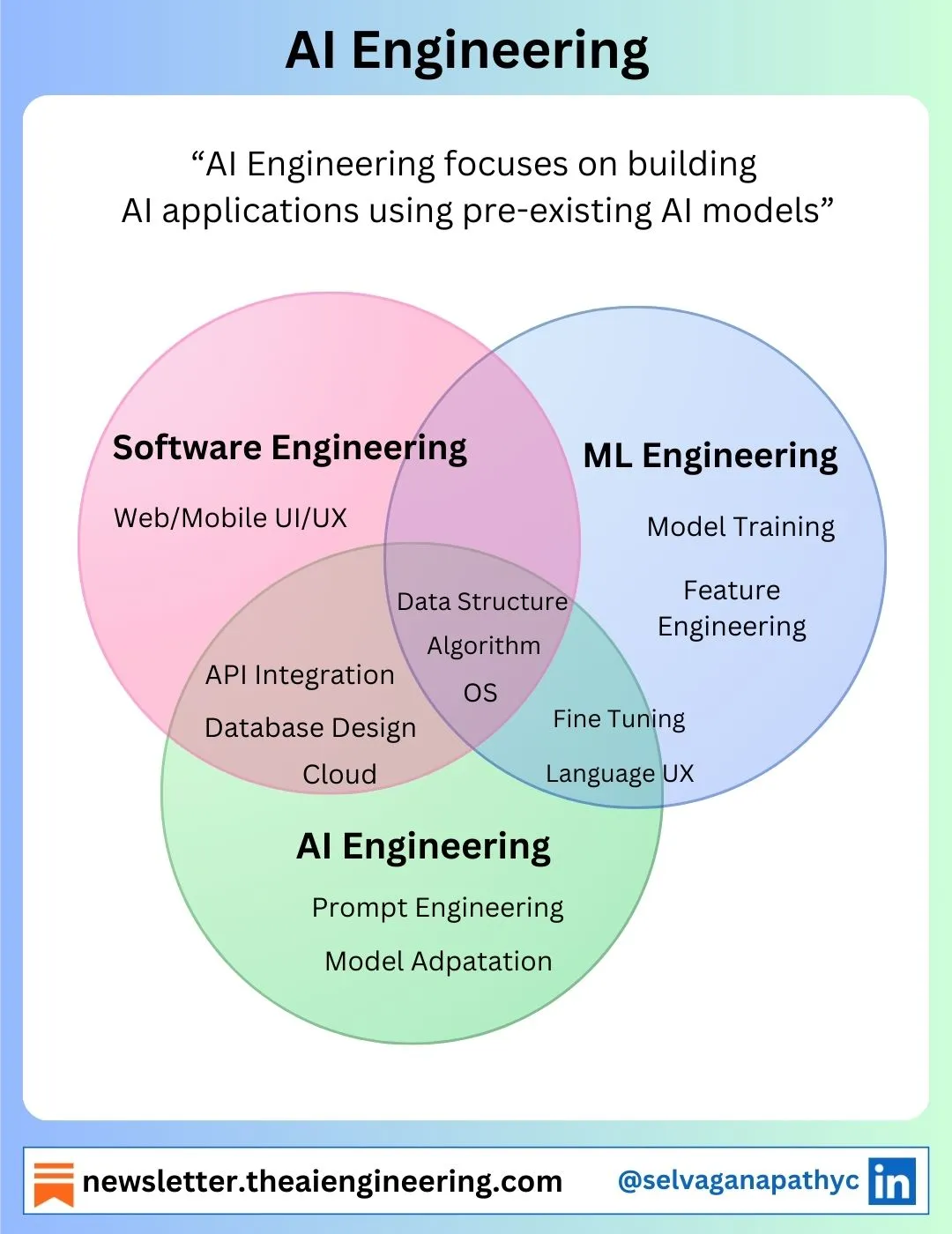
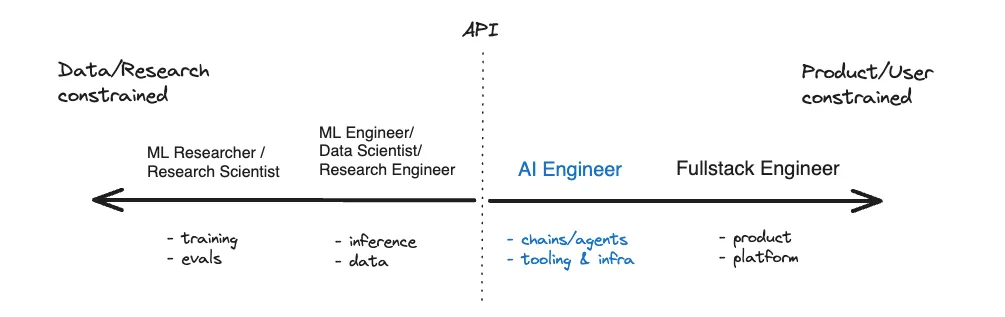
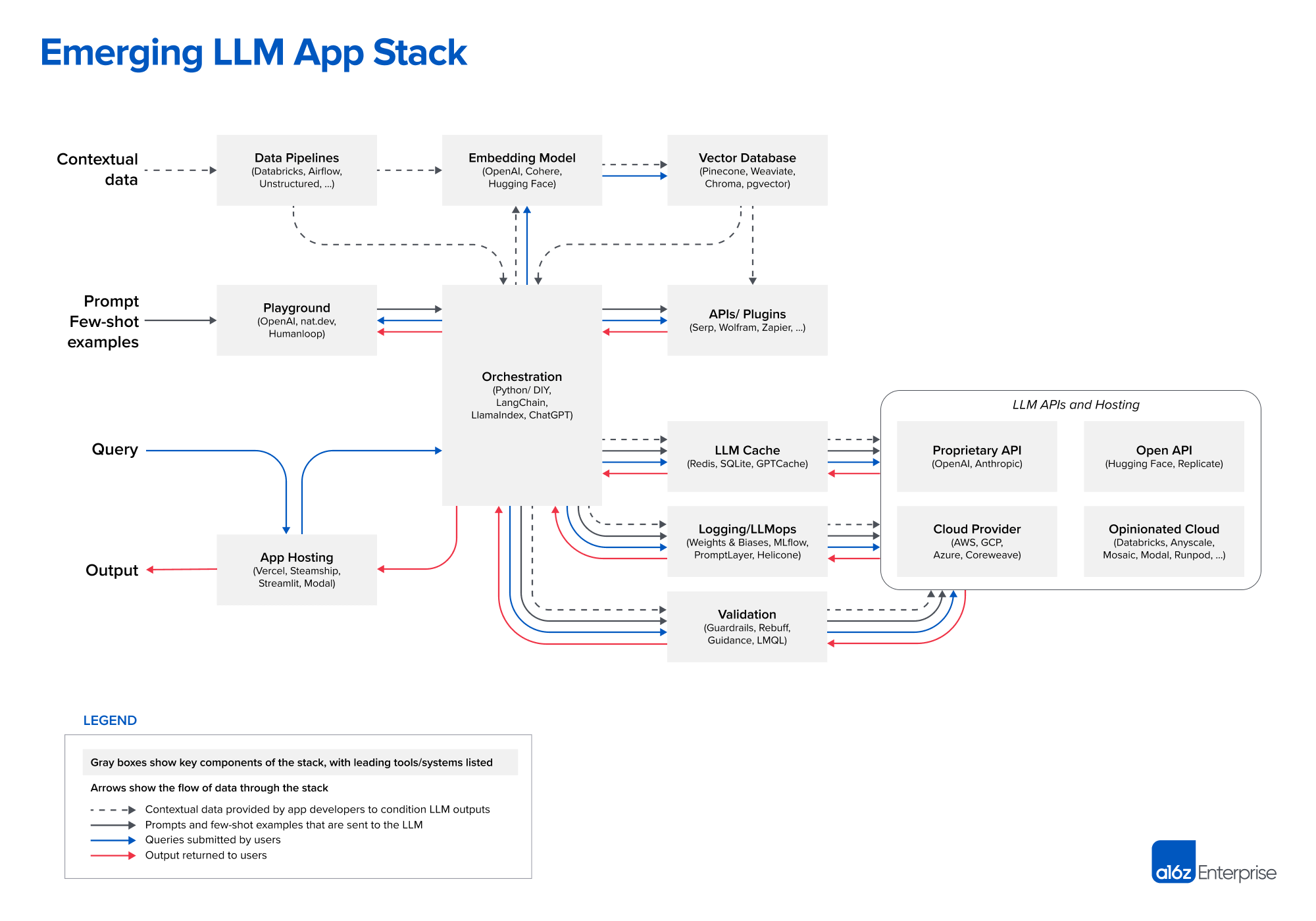
- AI Engineering stuff (might break out into a separate post)
- People to Follow
- Simon Willison
- Hamel Husein
- Shawn ‘swyx’ Wang
- Nir Diamant
- Ethan Mollick
- Andrew Ng
- Harrison Chase
- Jerry Liu
- Logan Kilpatrick
- Chip Huyen
- Cameron Wolfe
- Andrej Karpathy
- Lilian Weng (whose blog template I appropriated a few years ago, many thanks!)
- Heiko Hotz
- Andriy Burkov
- Latent Space Team
- Books