-
Practical ChatGPT Prompting: 15 Patterns to Improve Your Prompts
A logician is hiking through snowy woods and sees a small spaceship, and next to it, two tiny legs, sticking out of a snow drift. He digs the little creature out, and it turns out to be small omniscient space alien. The alien is extremely grateful and, being omniscient, offers to answer any question the logician may have. Naturally the logician asks: “What is the best question to ask and what is the correct answer to that question?” The tiny alien pauses momentarily, and replies, “The best question is the one you just asked; and the correct answer is this one.” And just like that…the alien hops in their spaceship and flies away.

Image via Dall-E: An image in the style of an arty Japanese animated film with vibrant colors, side view of a young lady sitting at a desk in front of a laptop in a library, looking dreamy and inquisitive. On her laptop screen, a futuristic robot is depicted sitting at a sleek desk facing the young lady. -
OpenAI DevDay
OpenAI is moving fast and extending their lead.
-
Truth, Lies, and ChatGPT
There are three kinds of lies: lies, damned lies, and statistics. - Mark Twain

-
Bullshit
That was just bullshit, Joel. - Miles, in Risky Business (1983)
History is a set of lies agreed upon. - Napoleon Bonaparte
Bullshit is the glue that binds us as a nation. - George Carlin

-
ChatGPT, OpenAI, and the Generative AI Revolution
I think it’s comparable in scale with the Industrial Revolution or electricity — or maybe the wheel. - Geoffrey Hinton
Any sufficiently advanced technology is indistinguishable from magic. - Arthur C. Clarke
GPT is a transformer so smart / That can write like a human or a bard / It can answer your queries / Or make stories so eerie / That you’ll wonder if it has a heart - GPT
-
NYC Subways and the Terrible, Horrible, No Good, Very Bad, Turnstile Data
The future ain’t what it used to be. - Yogi Berra
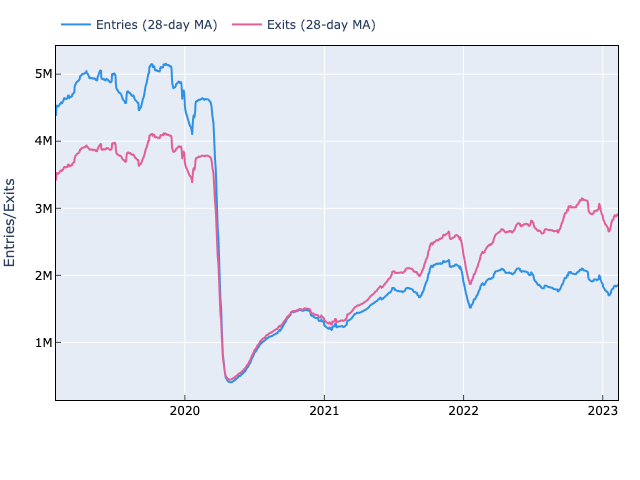
-
Numbers With Wings: A Modern Data Stack-In-A-Box
Not everything that counts can be counted, and not everything that can be counted counts. - Albert Einstein
There are three kinds of people: those who can count, and those who can’t. - Source unknown
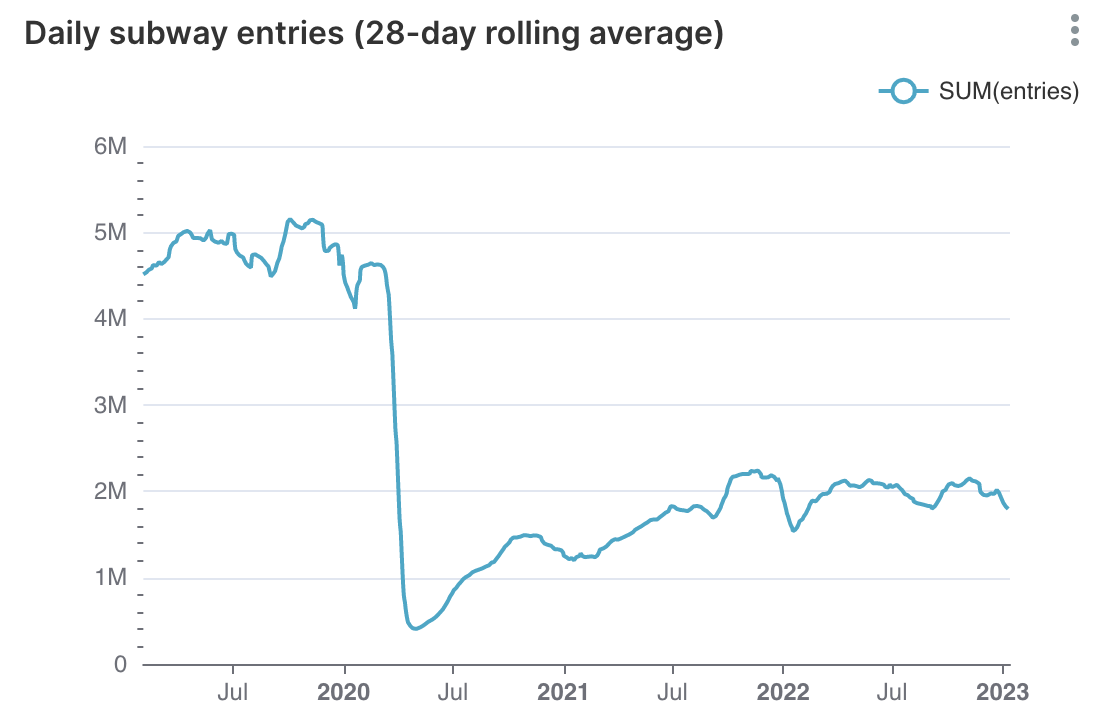
-
Kant, Nietzsche, Elon Musk, SBF, wokeness, and the categorical imperative
I beseech you, in the bowels of Christ, think it possible you may be mistaken. - Oliver Cromwell
-
Time Series Analysis In Theory
- A regular time series is a function from integers to real numbers: \(y_t = f(t)\).
- Many useful time series can be specified using linear difference equations like \(y_t = k_1y_{t-1} + k_2y_{t-2} + \dots + k_ny_{t-n}\)
- This recurrence relation has a characteristic equation (and matrix representation), whose roots (or matrix eigenvalues) can be used to write closed-form solutions like \(y_t=ax^t\).
- Any time series combining exponential growth/decay and sinusoidal components can be modeled by a linear difference equation or its matrix representation.
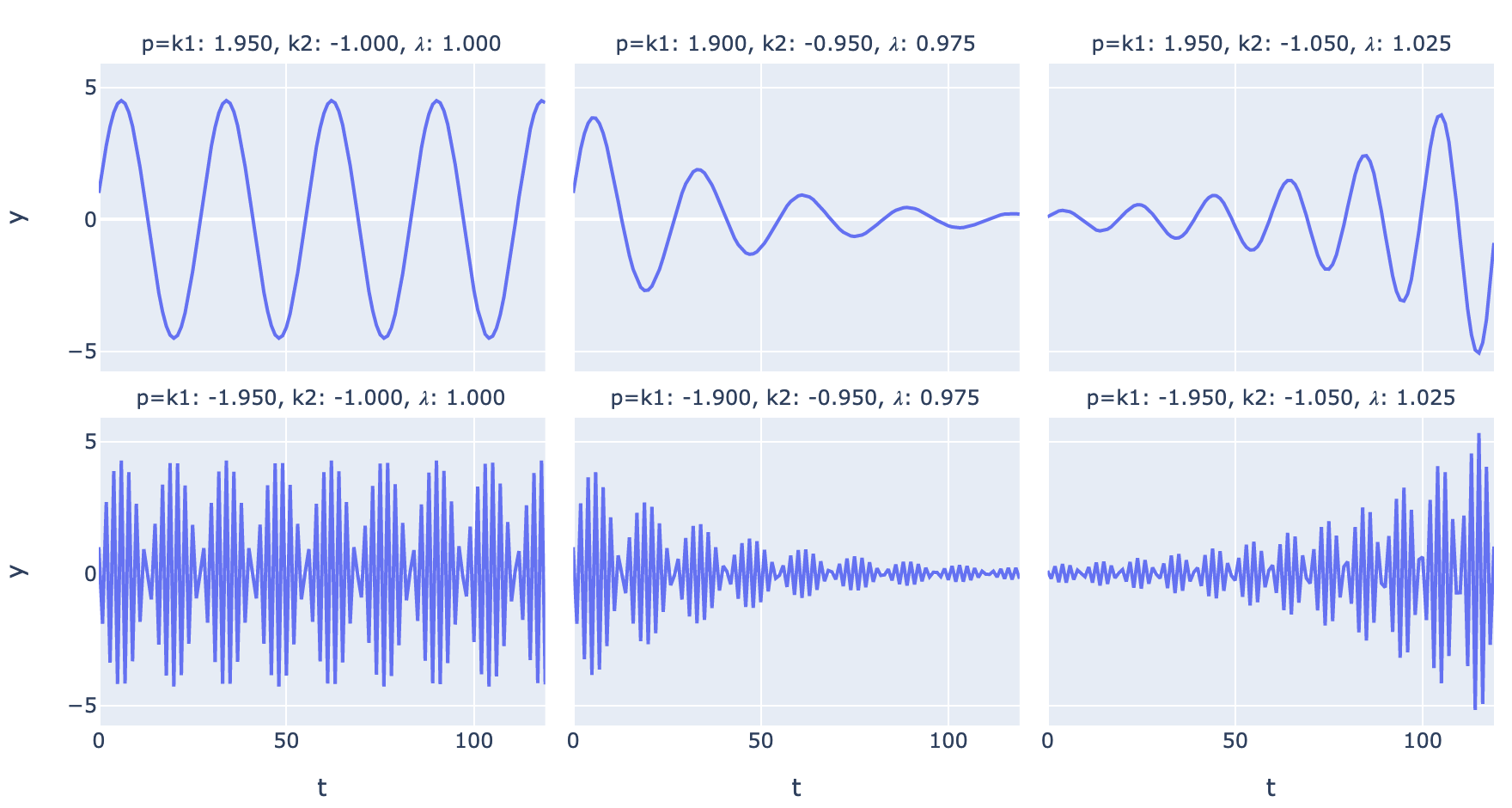
Fig. 1. Possible regimes for a 2nd-order linear difference equation with complex eigenvalues -
How I learned to stop worrying and love PCA: The optimal threshold for PCA dimensionality reduction
PCA is an essential data science tool which uses the SVD to break down the linear relationships in data. The Gavish-Donoho optimal truncation threshold provides a simple formula to select a good threshold for dimensionality reduction.
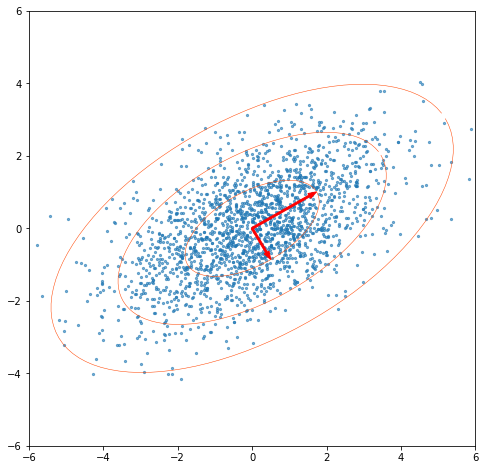
Fig. 1. A random 2D data set with singular vectors scaled by singular values -
Crypto systems, iron laws, and levels of resilience
Meditating on practical open distributed computing, how to build un-take-down-able apps like Web3 but without permissionless blockchains.
-
The AI Hierarchy of Needs
The perpetual challenge is building upper tiers before lower tiers are 100%, and strengthening lower tiers without breaking upper tiers.

-
Optimal Safe Withdrawal for Retirement Using Certainty-Equivalent Spending, Revisited
Revisiting Bengen’s “4% Rule” at various levels of risk aversion, and generalizing beyond a simple fixed-withdrawal, no-shortfall rule, to flexible rules at different levels of risk aversion.
-
What I would have written if I were Jack Dorsey
“Our decision to permanently suspend Donald Trump from the Twitter platform, may be a major inflection point in Twitter’s history. As CEO, I owe our users and employees a clear statement of why we took this action and how this decision evolved, i.e. not just some pablum about what a hard decision and potentially dangerous decision it was.”
-
Demystifying Portfolio Optimization with Python and CVXOPT
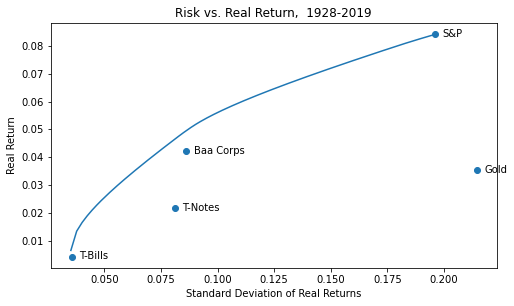
Do you want to do fast and easy portfolio optimization with Python? Then CVXOPT, and this post, are for you! Here’s a gentle intro to portfolio theory and some code to get you started.